
Table of Content
In this field of computer vision and insight, researchers have frequently revealed the benefit of transfer learning — pre-training a neural network design on a familiar task, for example, ImageNet, and then performing fine-tuning — utilizing the trained neural network as the foundation of a new and latest purpose-specific model. Researchers in recent years have also shown that a related technique can be beneficial in several natural language tasks.
There’s a lot of hype and other misinformation regarding the new Google algorithm update. What is BERT, how does it work, and why does it matter to our work as SEOs? In fact, during the prior year of its implementation, BERT created an exciting storm of activity in the production search. Under this article, we will explore what is BERT and the application of BERT toward text classification in python.
Google’s latest algorithmic update, BERT, serves Google to understand natural language adequately, especially in conversational search. BERT influences about 10% of queries and will also transform featured snippets and organic rankings. So, this is no small change. However, understand that BERT is not simply an algorithmic update, but it is also a research paper and machine learning natural language processing framework.
Also, read: 10 Powerful AI Chatbot Development Frameworks
What is BERT?
BERT stands for Bidirectional Encoder Representations from Transformers. It is a powerful and game-changing NLP framework from Google. It’s more commonly known as a Google search algorithm tool or framework named Google BERT which intends to improve search better, understand the distinction and meaning of words in searches, and better match any queries with effective and helpful results.
BERT is an open-source research and analysis project, and academic paper. It was first announced in October 2018 as BERT. Additionally, BERT is a natural language processing NLP framework produced by Google and next open-sourced research project, for making the complete natural language processing research field better at overall natural language understanding.
BERT has a major role in accelerating natural language understanding NLU more than any other framework, and Google’s progress towards open-source BERT has reasonably changed natural language processing permanently.
BERT has caused excitement in the Machine Learning and NLP community by offering state-of-the-art returns in a broad variety of NLP assignments, like Natural Language Inference (MNLI), Question Answering (SQuAD v1.1), and several others.
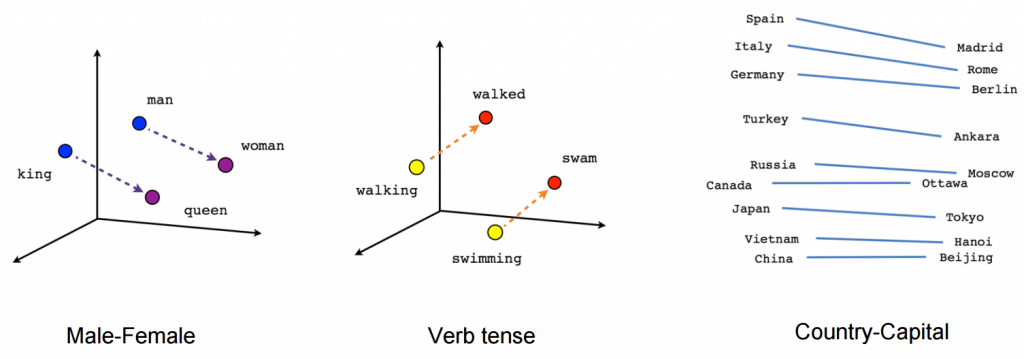
BERT’s key technical innovation implements the bidirectional training of Transformer, a modern attention model, to language modelling. This is in contrast to earlier efforts which looked at a text sequence either from left to right or combined left-to-right and right-to-left training. This paper’s outcomes reveal that a language model which is bi-directionally trained can possess a more profound sense of language flow and context than single-direction language models. The researchers detail a novel technique in the paper, named Masked LM (MLM) which now supports bidirectional training in models which was impossible earlier.
Also, read: Is Artificial Intelligence Development Expensive?
How BERT works
The purpose of any given NLP technique is to learn the human language as it is expressed naturally. In the case of BERT, this means predicting a word in a blank. To achieve this, models typically need to practice using a huge depository of specific, labelled training data. This requires laborious manual data labelling by teams of linguists.
BERT continues to learn unsupervised from the unlabeled text and grow even as it is used in practical applications i.e. Google search. Its pre-training works as a foundation layer of “knowledge” to develop from. From there, BERT can adjust to the ever-growing collection of searchable content and queries and be fine-tuned as per the user’s specifications. This process is called transfer learning.
BERT is additionally the first NLP technique to rely individually on the self-attention mechanism, which is made possible by the bidirectional transformers at the Centre of BERT’s design. This is important because usually, a word may alter its meaning as a sentence structure. If there are more total number of words present in every phrase or sentence, then the word which is in focus becomes more ambiguous. BERT accounts for the prolonged meaning by inspecting bidirectionally, accounting for the impact that all other words inside that sentence have on the focus word, plus removing the left-to-right momentum that otherwise biases words towards a definite meaning as the sentence proceeds.
Implementing BERT for Text Classification in Python
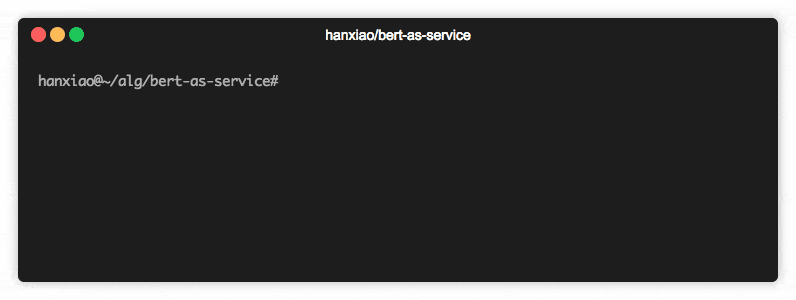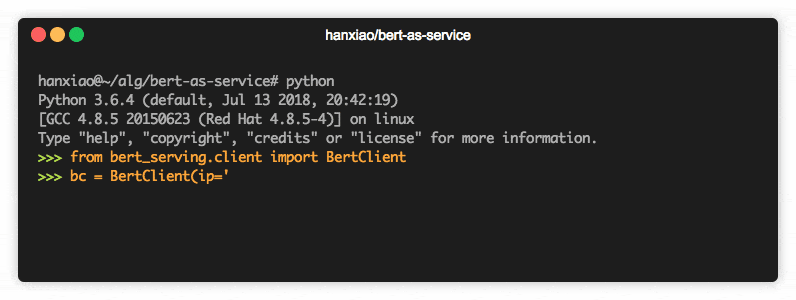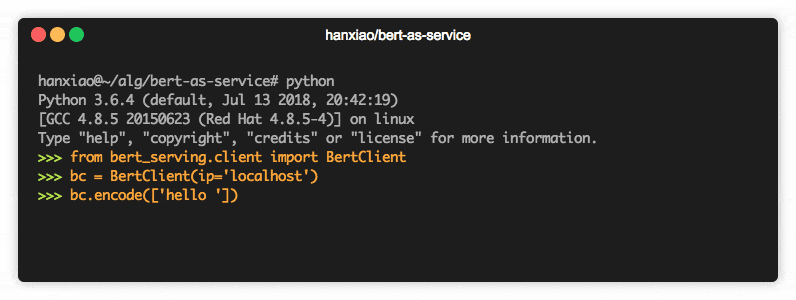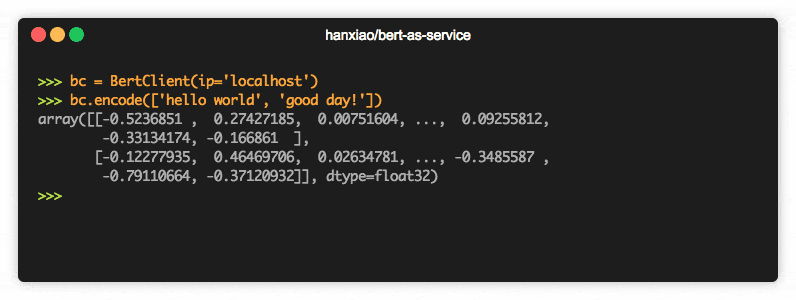
Text classification is the foundation of several text processing applications and is utilized in many various domains such as market human resources, CRM (consumer complaints routing, research, and science (classification of patient medical status), or social network monitoring (real-time emergency monitoring, fake information spotting, or any offensive comments).
Text classification models have gained remarkable outcomes thanks to the arrival of extremely performant Deep Learning NLP techniques, among which the BERT model and additional consorts have a leading role.
Now you must be thinking about all the opened-up possibilities that are provided by BERT. There are several ways we can take benefit of BERT’s huge repository of knowledge for our NLP applications. One of the most effective methods would be to fine-tune it for your particular task and task-specific data. You can next utilize these embeddings produced from BERT as embeddings for your text documents.
To pre-process your text just means to bring your text into a form that is analyzable and predictable for your task. A task here is a mixture of domain and approach. For instance, selecting the best keywords from Tweets (domain) with TF-IDF (approach) is an illustration of a task.
Final Takeaways:
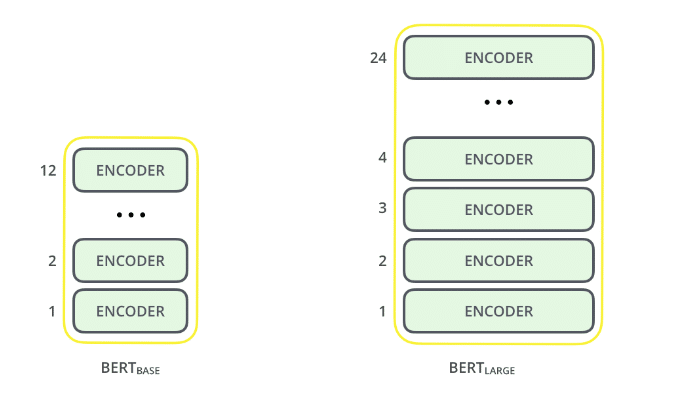
1. Model size matters, even on a large scale. BERT large, with around 345 million parameters, is the most comprehensive model of its kind. It is demonstrably better on small-scale tasks to BERT base, which utilizes the identical architecture with “just” 110 million parameters.
2. BERT’s bidirectional method (MLM) converges slower than left-to-right approaches (as just 15% of words are predicted in every batch) but bidirectional training still beats left-to-right training after a small number of pre-training steps.
3. With sufficient training data, more training steps, which ultimately leads to higher accuracy.
Conclusion
This article was primarily to explain the main ideas of the paper while not drowning in extreme technical aspects, here we have discussed BERT and its Text Classification in Python.
BERT is unquestionably a breakthrough and at the same time an invention in the use of Machine Learning for Natural Language Processing. The point that it’s approachable and provides fast fine-tuning will probably provide a broad range of practical applications in the future.
Source: What is BERT | BERT For Text Classification (analyticsvidhya.com)

AI Consulting Services
Planning to Leverage AI for your business? We provide AI Consulting to help organization implement this technology. Connect with our team to learn more.