
جدول المحتويات
في هذا المجال من رؤية الكمبيوتر والبصيرة ، كشف الباحثون بشكل متكرر عن فائدة نقل التعلم - التدريب المسبق لتصميم شبكة عصبية على مهمة مألوفة ، على سبيل المثال ، ImageNet ، ثم إجراء ضبط دقيق - باستخدام الشبكة العصبية المدربة باعتبارها تأسيس نموذج جديد وأحدث خاص بالغرض. أظهر الباحثون في السنوات الأخيرة أيضًا أن التقنية ذات الصلة يمكن أن تكون مفيدة في العديد من مهام اللغة الطبيعية.
هناك الكثير من الضجيج والمعلومات الخاطئة الأخرى المتعلقة بتحديث خوارزمية Google الجديد. ما هو BERT ، وكيف يعمل ، ولماذا يهم عملنا كمحسّنات محرّكات البحث؟ في الواقع ، خلقت BERT عاصفة مثيرة من النشاط في البحث عن الإنتاج خلال العام السابق لتنفيذه. في إطار هذه المقالة ، سوف نستكشف ما هو BERT وتطبيق BERT لتصنيف النص في Python.
آخر تحديث خوارزمي من Google ، BERT ، يخدم Google لفهم اللغة الطبيعية بشكل مناسب ، لا سيما في البحث التخاطبي. يؤثر BERT على حوالي 10٪ من الاستعلامات وسيحول أيضًا المقتطفات المميزة والتصنيفات العضوية. لذا ، هذا ليس تغييرًا بسيطًا. ومع ذلك ، افهم أن BERT ليس مجرد تحديث خوارزمي ، ولكنه أيضًا ورقة بحث وإطار عمل معالجة اللغة الطبيعية لتعلم الآلة.
أيضا ، اقرأ: 10 أطر تطوير قوية لروبوتات الدردشة AI
ما هو بيرت؟
يرمز BERT إلى تمثيلات التشفير ثنائي الاتجاه من المحولات. إنه إطار عمل قوي ومتغير للعبة البرمجة اللغوية العصبية من Google. يُعرف بشكل أكثر شيوعًا باسم أداة أو إطار عمل خوارزمية بحث Google المسمى Google BERT والذي يهدف إلى تحسين البحث بشكل أفضل ، وفهم تمييز ومعنى الكلمات في عمليات البحث ، ومطابقة أي استعلامات بشكل أفضل بنتائج فعالة ومفيدة.
BERT هو مشروع بحث وتحليل مفتوح المصدر وورقة أكاديمية. تم الإعلان عنه لأول مرة في أكتوبر 2018 باسم BERT. بالإضافة إلى ذلك ، BERT عبارة عن إطار عمل NLP لمعالجة اللغة الطبيعية أنتجته Google ومشروع بحث مفتوح المصدر التالي ، لجعل مجال أبحاث معالجة اللغة الطبيعية الكامل أفضل في فهم اللغة الطبيعية بشكل عام.
يلعب BERT دورًا رئيسيًا في تسريع فهم اللغة الطبيعية NLU أكثر من أي إطار عمل آخر ، وقد أدى تقدم Google نحو BERT مفتوح المصدر إلى تغيير معالجة اللغة الطبيعية بشكل معقول بشكل دائم.
تسبب BERT في الإثارة في مجتمع التعلم الآلي ومعالجة اللغات الطبيعية من خلال تقديم أحدث العوائد في مجموعة متنوعة من مهام البرمجة اللغوية العصبية ، مثل الاستدلال اللغوي الطبيعي (MNLI) والإجابة على الأسئلة (SQuAD v1.1) والعديد من المهام الأخرى.
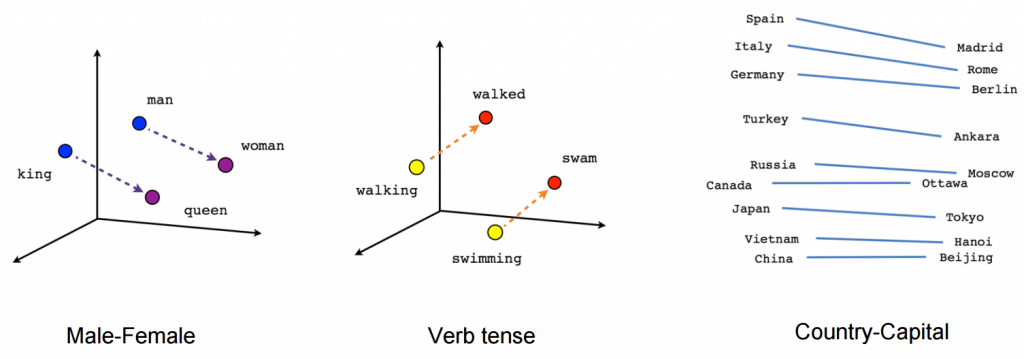
ينفذ الابتكار التقني الرئيسي لـ BERT التدريب ثنائي الاتجاه لـ Transformer ، وهو نموذج اهتمام حديث ، لنمذجة اللغة. هذا على عكس الجهود السابقة التي نظرت في تسلسل نصي إما من اليسار إلى اليمين أو التدريب من اليسار إلى اليمين ومن اليمين إلى اليسار. تكشف نتائج هذه الورقة أن نموذج اللغة الذي يتم تدريبه ثنائي الاتجاه يمكن أن يمتلك إحساسًا أكثر عمقًا بتدفق اللغة والسياق من نماذج اللغة أحادية الاتجاه. قام الباحثون بتفصيل تقنية جديدة في الورقة ، تسمى Masked LM (MLM) والتي تدعم الآن التدريب ثنائي الاتجاه في النماذج التي كانت مستحيلة في وقت سابق.
أيضا ، اقرأ: هل تطوير الذكاء الاصطناعي مكلف؟
كيف يعمل بيرت
الغرض من أي أسلوب معين في البرمجة اللغوية العصبية هو تعلم اللغة البشرية كما يتم التعبير عنها بشكل طبيعي. في حالة BERT ، هذا يعني التنبؤ بكلمة فارغة. لتحقيق ذلك ، تحتاج النماذج عادةً إلى التدرب على استخدام مستودع ضخم لبيانات تدريب محددة ومُعنونة. وهذا يتطلب تصنيف البيانات اليدوي الشاق من قبل فرق اللغويين.
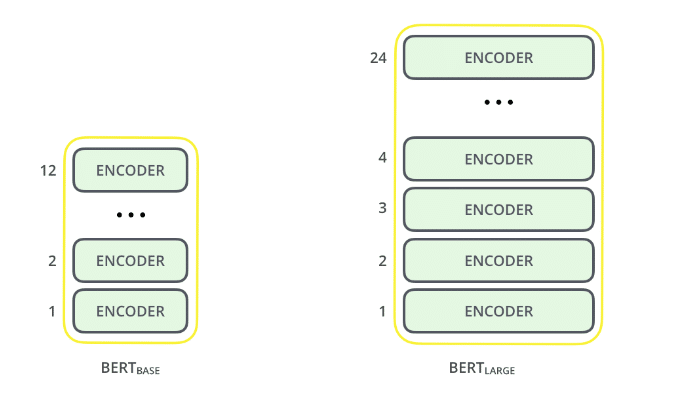
يواصل BERT التعلم من النص غير الخاضع للإشراف وينمو حتى مع استخدامه في التطبيقات العملية مثل بحث Google. يعمل ما قبل التدريب كطبقة أساسية من "المعرفة" للتطوير منها. من هناك ، يمكن لـ BERT التكيف مع المجموعة المتزايدة باستمرار من المحتوى والاستفسارات القابلة للبحث ويتم ضبطها وفقًا لمواصفات المستخدم. هذه العملية تسمى نقل التعلم.
تعد BERT أيضًا أول تقنية معالجة لغوية طبيعية تعتمد بشكل فردي على آلية الانتباه الذاتي ، والتي أصبحت ممكنة بواسطة المحولات ثنائية الاتجاه في تصميم مركز BERT. هذا مهم لأنه عادة ، يمكن للكلمة أن تغير معناها كبنية للجملة. إذا كان هناك عدد إجمالي أكبر من الكلمات الموجودة في كل عبارة أو جملة ، فإن الكلمة التي يتم التركيز عليها تصبح أكثر غموضًا. يفسر BERT المعنى المطول من خلال الفحص ثنائي الاتجاه ، مع مراعاة تأثير جميع الكلمات الأخرى داخل تلك الجملة على الكلمة المركزة ، بالإضافة إلى إزالة الزخم من اليسار إلى اليمين الذي يحيز الكلمات نحو معنى محدد مع استمرار الجملة.
تطبيق BERT لتصنيف النص في Python
تصنيف النص هو الأساس للعديد من تطبيقات معالجة النصوص ويتم استخدامه في العديد من المجالات المختلفة مثل الموارد البشرية للسوق ، وإدارة علاقات العملاء (توجيه شكاوى المستهلكين ، والبحث ، والعلوم (تصنيف الحالة الطبية للمريض) ، أو مراقبة الشبكة الاجتماعية (الطوارئ في الوقت الفعلي المراقبة أو اكتشاف معلومات مزيفة أو أي تعليقات مسيئة).
اكتسبت نماذج تصنيف النص نتائج ملحوظة بفضل وصول تقنيات البرمجة اللغوية العصبية للتعلم العميق عالية الأداء ، ومن بينها نموذج BERT والأتباع الإضافيون الذين يلعبون دورًا رائدًا.
الآن يجب أن تفكر في جميع الاحتمالات المفتوحة التي يوفرها BERT. هناك عدة طرق يمكننا من خلالها الاستفادة من مستودع المعرفة الضخم لـ BERT لتطبيقات البرمجة اللغوية العصبية الخاصة بنا. تتمثل إحدى الطرق الأكثر فاعلية في ضبطها وفقًا لمهمة معينة وبيانات خاصة بالمهمة. يمكنك بعد ذلك الاستفادة من هذه الزخارف المنتجة من BERT كزفاف في مستنداتك النصية.
تعني المعالجة المسبقة للنص فقط إحضار النص إلى شكل يمكن تحليله والتنبؤ به لمهمتك. المهمة هنا هي مزيج من المجال والنهج. على سبيل المثال ، يعد اختيار أفضل الكلمات الرئيسية من التغريدات (المجال) باستخدام TF-IDF (نهج) توضيحًا لمهمة ما.
الوجبات الجاهزة النهائية:
1. حجم النموذج مهم ، حتى على نطاق واسع. BERT كبير ، مع حوالي 345 مليون معلمة ، هو النموذج الأكثر شمولاً من نوعه. من الواضح أنه أفضل في المهام الصغيرة لقاعدة BERT ، والتي تستخدم بنية متطابقة مع 110 مليون معلمة "فقط".
2. أسلوب BERT ثنائي الاتجاه (MLM) يتقارب بشكل أبطأ من النهج من اليسار إلى اليمين (حيث يتم توقع 15٪ فقط من الكلمات في كل دفعة) ولكن لا يزال التدريب ثنائي الاتجاه يتفوق على التدريب من اليسار إلى اليمين بعد عدد صغير من خطوات ما قبل التدريب .
3. مع بيانات تدريب كافية ، خطوات تدريب أكثر ، مما يؤدي في النهاية إلى دقة أعلى.
وفي الختام
كانت هذه المقالة في المقام الأول لشرح الأفكار الرئيسية للورقة مع عدم الغرق في الجوانب التقنية المتطرفة ، لقد ناقشنا هنا BERT وتصنيف النص الخاص به في Python.
BERT هو بلا شك اختراق وفي نفس الوقت اختراع في استخدام التعلم الآلي لمعالجة اللغة الطبيعية. من المحتمل أن توفر النقطة التي يمكن الوصول إليها وتوفر ضبطًا سريعًا مجموعة واسعة من التطبيقات العملية في المستقبل.
المصدر ما هو BERT | بيرت لتصنيف النص (analyticsvidhya.com)

خدمات استشارات الذكاء الاصطناعي
هل تخطط للاستفادة من الذكاء الاصطناعي في عملك؟ نحن نقدم استشارات الذكاء الاصطناعي لمساعدة المنظمة في تطبيق هذه التكنولوجيا. تواصل مع فريقنا لمعرفة المزيد.