
Tabela de conteúdo
Neste campo de visão computacional e visão, os pesquisadores frequentemente revelam o benefício da aprendizagem por transferência - pré-treinar um projeto de rede neural em uma tarefa familiar, por exemplo, ImageNet, e então realizar o ajuste fino - utilizando a rede neural treinada como o fundação de um novo e mais recente modelo específico para o propósito. Pesquisadores nos últimos anos também mostraram que uma técnica relacionada pode ser benéfica em várias tarefas de linguagem natural.
Há muito hype e outras informações incorretas sobre a nova atualização do algoritmo do Google. O que é BERT, como funciona e por que é importante para o nosso trabalho como SEOs? Na verdade, durante o ano anterior de sua implementação, o BERT criou uma tempestade emocionante de atividades na busca de produção. Neste artigo, exploraremos o que é BERT e a aplicação do BERT na classificação de textos em python.
A última atualização algorítmica do Google, BERT, serve ao Google para entender a linguagem natural de forma adequada, especialmente em busca de conversação. O BERT influencia cerca de 10% das consultas e também transformará snippets em destaque e classificações orgânicas. Portanto, esta não é uma mudança pequena. No entanto, entenda que o BERT não é simplesmente uma atualização algorítmica, mas também um trabalho de pesquisa e um framework de processamento de linguagem natural de aprendizado de máquina.
Além disso, leia: 10 poderosos AI Chatbot Development Frameworks
O que é BERT?
BERT significa Bidirectional Encoder Representations from Transformers. É uma estrutura de PNL poderosa e revolucionária do Google. É mais comumente conhecido como uma ferramenta de algoritmo de pesquisa do Google ou estrutura chamada Google BERT que visa melhorar a pesquisa, entender a distinção e o significado das palavras nas pesquisas e corresponder melhor a quaisquer consultas com resultados eficazes e úteis.
BERT é um projeto de pesquisa e análise de código aberto e trabalho acadêmico. Foi anunciado pela primeira vez em outubro de 2018 como BERT. Além disso, o BERT é uma estrutura de PNL de processamento de linguagem natural produzida pelo Google e o próximo projeto de pesquisa de código aberto, para tornar o campo de pesquisa de processamento de linguagem natural completo melhor no entendimento geral da linguagem natural.
O BERT tem um papel importante na aceleração do entendimento da linguagem natural NLU mais do que qualquer outra estrutura, e o progresso do Google em direção ao BERT de código aberto mudou razoavelmente o processamento da linguagem natural de forma permanente.
BERT causou entusiasmo na comunidade de aprendizado de máquina e PNL, oferecendo retornos de última geração em uma ampla variedade de atribuições de PNL, como Inferência de linguagem natural (MNLI), resposta a perguntas (SQuAD v1.1) e vários outros.
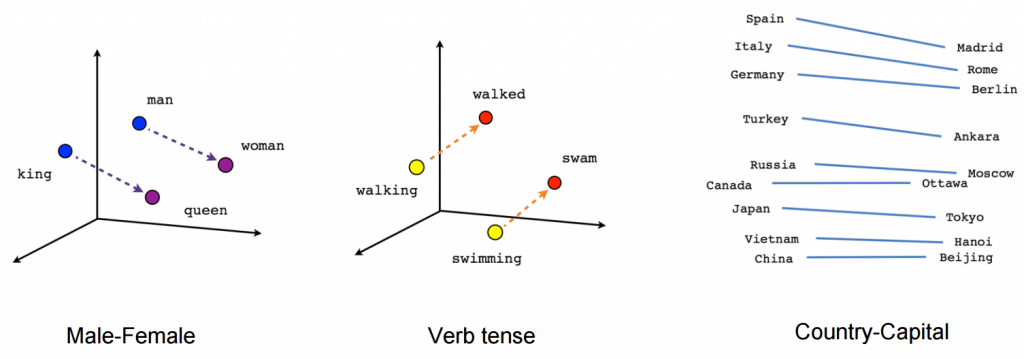
A principal inovação técnica do BERT implementa o treinamento bidirecional do Transformer, um modelo moderno de atenção à modelagem de linguagem. Isso está em contraste com os esforços anteriores que olhavam para uma sequência de texto da esquerda para a direita ou treinamento combinado da esquerda para a direita e da direita para a esquerda. Os resultados deste artigo revelam que um modelo de linguagem que é treinado bidirecionalmente pode possuir um senso mais profundo de fluxo de linguagem e contexto do que modelos de linguagem de uma direção. Os pesquisadores detalham uma nova técnica no artigo, chamada Masked LM (MLM), que agora oferece suporte a treinamento bidirecional em modelos que antes era impossível.
Além disso, leia: O desenvolvimento de inteligência artificial é caro?
Como funciona o BERT
O propósito de qualquer técnica de PNL é aprender a linguagem humana como ela é expressa naturalmente. No caso do BERT, isso significa prever uma palavra em branco. Para conseguir isso, os modelos normalmente precisam praticar o uso de um grande depósito de dados de treinamento específicos e rotulados. Isso requer uma laboriosa rotulagem manual de dados por equipes de linguistas.
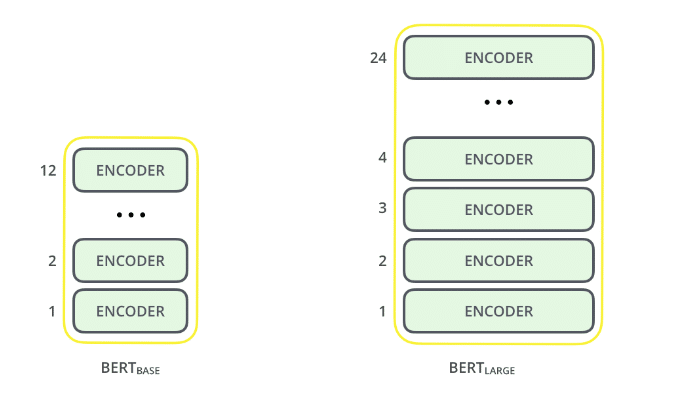
O BERT continua a aprender sem supervisão com o texto não rotulado e a crescer à medida que é usado em aplicações práticas, por exemplo, pesquisa do Google. Seu pré-treinamento funciona como uma camada básica de “conhecimento” a partir da qual se desenvolver. A partir daí, o BERT pode se ajustar à coleção cada vez maior de conteúdo pesquisável e consultas e ser ajustado de acordo com as especificações do usuário. Este processo é denominado aprendizagem por transferência.
Além disso, o BERT é a primeira técnica de PNL a contar individualmente com o mecanismo de autoatenção, que é possível graças aos transformadores bidirecionais do Centro de design do BERT. Isso é importante porque, normalmente, uma palavra pode alterar seu significado como uma estrutura de frase. Se houver mais número total de palavras presentes em cada frase ou sentença, a palavra em foco torna-se mais ambígua. O BERT explica o significado prolongado inspecionando bidirecionalmente, levando em consideração o impacto que todas as outras palavras dentro dessa frase têm na palavra em foco, além de remover o momentum da esquerda para a direita que, de outra forma, distorce as palavras em direção a um significado definido conforme a frase prossegue.
Implementando BERT para classificação de texto em Python
A classificação de texto é a base de vários aplicativos de processamento de texto e é utilizada em vários domínios, como recursos humanos de mercado, CRM (encaminhamento de reclamações do consumidor, pesquisa e ciência (classificação do estado médico do paciente) ou monitoramento de rede social (emergência em tempo real monitoramento, localização de informações falsas ou quaisquer comentários ofensivos).
Os modelos de classificação de texto obtiveram resultados notáveis graças à chegada de técnicas de PNL de aprendizado profundo de extrema performance, entre as quais o modelo BERT e consortes adicionais têm um papel de liderança.
Agora você deve estar pensando em todas as possibilidades abertas que são fornecidas pelo BERT. Existem várias maneiras de nos beneficiarmos do enorme repositório de conhecimento do BERT para nossas aplicações de PNL. Um dos métodos mais eficazes seria ajustá-lo para sua tarefa particular e dados específicos da tarefa. Em seguida, você pode utilizar esses embeddings produzidos a partir do BERT como embeddings para seus documentos de texto.
Pré-processar seu texto significa apenas colocá-lo em uma forma que seja analisável e previsível para sua tarefa. Uma tarefa aqui é uma mistura de domínio e abordagem. Por exemplo, selecionar as melhores palavras-chave de Tweets (domínio) com TF-IDF (abordagem) é uma ilustração de uma tarefa.
Conclusões finais:
1. O tamanho do modelo é importante, mesmo em grande escala. O BERT grande, com cerca de 345 milhões de parâmetros, é o modelo mais completo de seu tipo. É comprovadamente melhor em tarefas de pequena escala para base de BERT, que utiliza a arquitetura idêntica com “apenas” 110 milhões de parâmetros.
2. O método bidirecional de BERT (MLM) converge mais lentamente do que as abordagens da esquerda para a direita (já que apenas 15% das palavras são previstas em cada lote), mas o treinamento bidirecional ainda supera o treinamento da esquerda para a direita após um pequeno número de etapas de pré-treinamento .
3. Com dados de treinamento suficientes, mais etapas de treinamento, o que leva a uma maior precisão.
Conclusão
Este artigo foi principalmente para explicar as idéias principais do artigo, sem nos afogar em aspectos técnicos extremos, aqui discutimos o BERT e sua Classificação de Texto em Python.
BERT é, sem dúvida, um avanço e ao mesmo tempo uma invenção no uso de Aprendizado de Máquina para Processamento de Linguagem Natural. O ponto de ser acessível e fornecer ajuste fino rápido provavelmente fornecerá uma ampla gama de aplicações práticas no futuro.
Fonte: O que é BERT | BERT para classificação de texto (analyticsvidhya.com)

Serviços de consultoria de IA
Planejando alavancar a IA para o seu negócio? Oferecemos AI Consulting para ajudar as organizações a implementar esta tecnologia. Conecte-se com nossa equipe para saber mais.