
Tabla de Contenido
En este campo de la visión y el conocimiento por computadora, los investigadores han revelado con frecuencia el beneficio del aprendizaje por transferencia: entrenando previamente un diseño de red neuronal en una tarea familiar, por ejemplo, ImageNet, y luego realizando un ajuste fino, utilizando la red neuronal entrenada como el base de un nuevo y último modelo específico para un propósito. Los investigadores en los últimos años también han demostrado que una técnica relacionada puede ser beneficiosa en varias tareas del lenguaje natural.
Hay mucha publicidad y otra información errónea con respecto a la nueva actualización del algoritmo de Google. ¿Qué es BERT, cómo funciona y por qué es importante para nuestro trabajo como SEO? De hecho, durante el año anterior a su implementación, BERT creó una excitante tormenta de actividad en la búsqueda de producción. En este artículo, exploraremos qué es BERT y la aplicación de BERT a la clasificación de texto en Python.
La última actualización algorítmica de Google, BERT, sirve a Google para comprender adecuadamente el lenguaje natural, especialmente en la búsqueda conversacional. BERT influye en aproximadamente el 10% de las consultas y también transformará los fragmentos destacados y las clasificaciones orgánicas. Entonces, este no es un cambio pequeño. Sin embargo, comprenda que BERT no es simplemente una actualización algorítmica, sino que también es un trabajo de investigación y un marco de procesamiento de lenguaje natural de aprendizaje automático.
También, lea: 10 potentes marcos de desarrollo de chatbot de IA
¿Qué es el BERT?
BERT son las siglas de Bidirectional Encoder Representations from Transformers. Es un marco de PNL poderoso y revolucionario de Google. Es más comúnmente conocido como una herramienta o marco de algoritmo de búsqueda de Google llamado Google BERT que tiene la intención de mejorar la búsqueda mejor, comprender la distinción y el significado de las palabras en las búsquedas y hacer coincidir mejor cualquier consulta con resultados efectivos y útiles.
BERT es un proyecto de investigación y análisis de código abierto y un artículo académico. Se anunció por primera vez en octubre de 2018 como BERT. Además, BERT es un marco de PNL de procesamiento de lenguaje natural producido por Google y el próximo proyecto de investigación de código abierto, para mejorar el campo completo de investigación del procesamiento del lenguaje natural en la comprensión general del lenguaje natural.
BERT tiene un papel importante en la aceleración de la comprensión del lenguaje natural NLU más que cualquier otro marco, y el progreso de Google hacia BERT de código abierto ha cambiado razonablemente el procesamiento del lenguaje natural de forma permanente.
BERT ha causado entusiasmo en la comunidad de aprendizaje automático y PNL al ofrecer retornos de última generación en una amplia variedad de asignaciones de PNL, como la inferencia del lenguaje natural (MNLI), la respuesta a preguntas (SQuAD v1.1) y muchas otras.
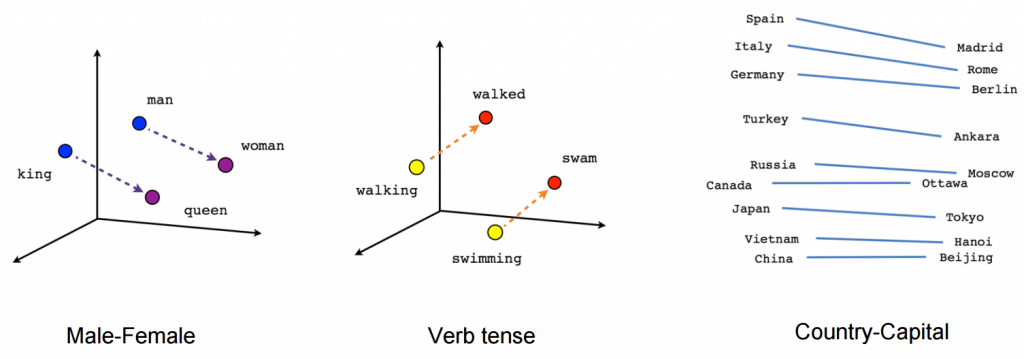
La innovación técnica clave de BERT implementa la capacitación bidireccional de Transformer, un modelo de atención moderno, para el modelado del lenguaje. Esto contrasta con los esfuerzos anteriores que analizaban una secuencia de texto de izquierda a derecha o una formación combinada de izquierda a derecha y de derecha a izquierda. Los resultados de este artículo revelan que un modelo de lenguaje que se entrena bidireccionalmente puede poseer un sentido más profundo del flujo del lenguaje y el contexto que los modelos de lenguaje de una sola dirección. Los investigadores detallan una técnica novedosa en el documento, llamada Masked LM (MLM) que ahora admite el entrenamiento bidireccional en modelos que antes era imposible.
También, lea: ¿Es caro el desarrollo de la inteligencia artificial?
Cómo funciona BERT
El propósito de cualquier técnica de PNL dada es aprender el lenguaje humano tal como se expresa de forma natural. En el caso de BERT, esto significa predecir una palabra en un espacio en blanco. Para lograr esto, los modelos generalmente necesitan practicar usando un gran depósito de datos de entrenamiento específicos y etiquetados. Esto requiere un laborioso etiquetado manual de datos por parte de equipos de lingüistas.
BERT continúa aprendiendo sin supervisión del texto sin etiquetar y crece incluso cuando se usa en aplicaciones prácticas, es decir, en la búsqueda de Google. Su pre-formación funciona como una capa fundamental de "conocimiento" a partir de la cual desarrollarse. A partir de ahí, BERT puede adaptarse a la colección cada vez mayor de contenido y consultas que se pueden buscar y ajustarse según las especificaciones del usuario. Este proceso se llama aprendizaje por transferencia.
BERT es además la primera técnica de PNL que se basa individualmente en el mecanismo de auto-atención, que es posible gracias a los transformadores bidireccionales en el centro del diseño de BERT. Esto es importante porque, por lo general, una palabra puede alterar su significado como estructura de una oración. Si hay más palabras presentes en cada frase u oración, entonces la palabra que está enfocada se vuelve más ambigua. BERT explica el significado prolongado inspeccionando bidireccionalmente, teniendo en cuenta el impacto que todas las demás palabras dentro de esa oración tienen en la palabra de enfoque, además de eliminar el impulso de izquierda a derecha que, de lo contrario, predispone las palabras hacia un significado definido a medida que avanza la oración.
Implementación de BERT para la clasificación de texto en Python
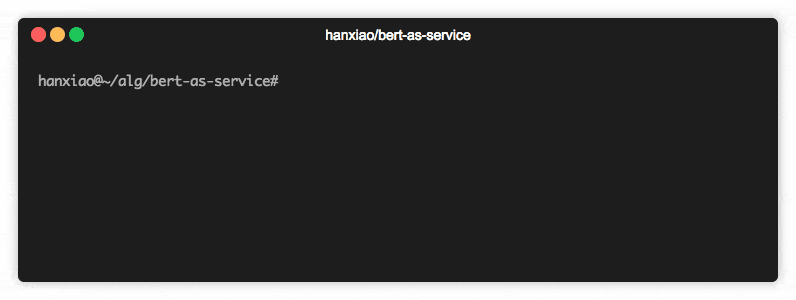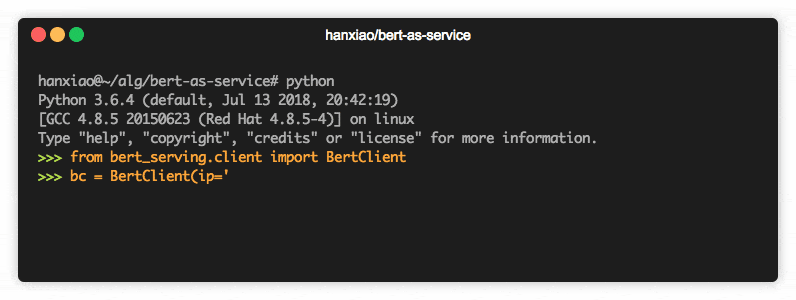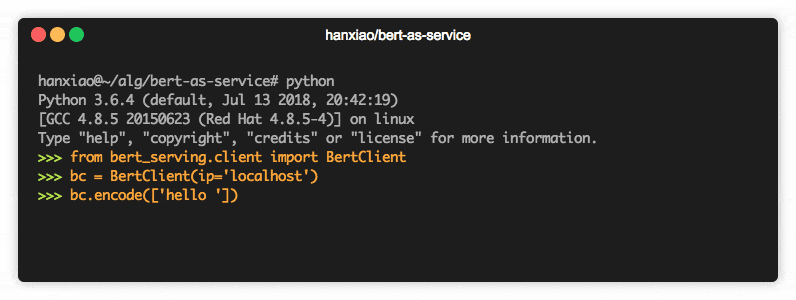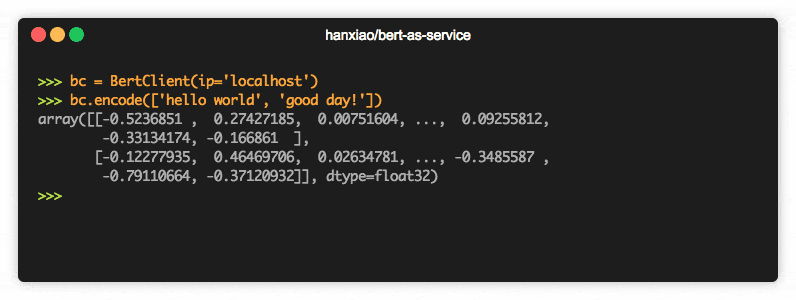
La clasificación de texto es la base de varias aplicaciones de procesamiento de texto y se utiliza en muchos dominios diversos, como recursos humanos del mercado, CRM (enrutamiento de quejas de los consumidores, investigación y ciencia (clasificación del estado médico del paciente) o monitoreo de redes sociales (emergencia en tiempo real). monitoreo, detección de información falsa o cualquier comentario ofensivo).
Los modelos de clasificación de texto han obtenido resultados notables gracias a la llegada de técnicas de PNL de aprendizaje profundo extremadamente eficaces, entre las que el modelo BERT y consortes adicionales tienen un papel principal.
Ahora debe estar pensando en todas las posibilidades abiertas que ofrece BERT. Hay varias formas en las que podemos beneficiarnos del enorme depósito de conocimientos de BERT para nuestras aplicaciones de PNL. Uno de los métodos más efectivos sería ajustarlo para su tarea particular y datos específicos de la tarea. A continuación, puede utilizar estas incrustaciones producidas a partir de BERT como incrustaciones para sus documentos de texto.
Procesar previamente su texto solo significa llevar su texto a una forma que sea analizable y predecible para su tarea. Una tarea aquí es una mezcla de dominio y enfoque. Por ejemplo, seleccionar las mejores palabras clave de Tweets (dominio) con TF-IDF (enfoque) es una ilustración de una tarea.
Conclusiones finales:
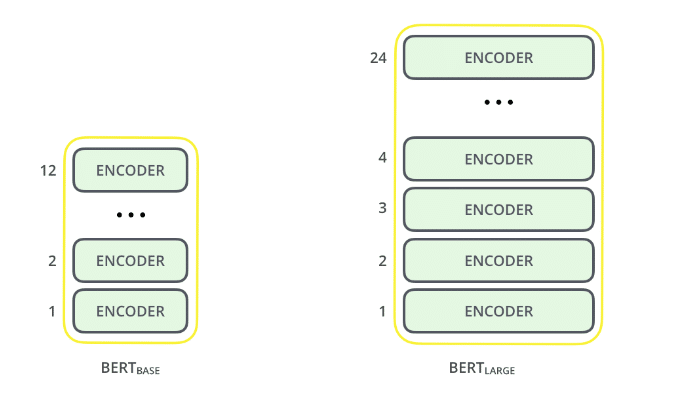
1. El tamaño del modelo importa, incluso a gran escala. BERT grande, con alrededor de 345 millones de parámetros, es el modelo más completo de su tipo. Es demostrablemente mejor en tareas de pequeña escala que la base de BERT, que utiliza la misma arquitectura con "solo" 110 millones de parámetros.
2. El método bidireccional (MLM) de BERT converge más lentamente que los enfoques de izquierda a derecha (ya que solo se predice el 15% de las palabras en cada lote), pero el entrenamiento bidireccional sigue ganando al entrenamiento de izquierda a derecha después de una pequeña cantidad de pasos previos al entrenamiento. .
3. Con suficientes datos de entrenamiento, más pasos de entrenamiento, lo que finalmente conduce a una mayor precisión.
Conclusión
Este artículo fue principalmente para explicar las ideas principales del artículo sin ahogarnos en aspectos técnicos extremos, aquí hemos discutido BERT y su clasificación de texto en Python.
BERT es sin duda un gran avance y, al mismo tiempo, una invención en el uso del aprendizaje automático para el procesamiento del lenguaje natural. El hecho de que sea accesible y proporcione un ajuste fino rápido probablemente proporcionará una amplia gama de aplicaciones prácticas en el futuro.
Fuente: Qué es BERT | BERT para clasificación de texto (analyticsvidhya.com)

Servicios de consultoría de IA
¿Planea aprovechar la IA para su negocio? Ofrecemos consultoría de inteligencia artificial para ayudar a la organización a implementar esta tecnología. Conéctese con nuestro equipo para obtener más información.